SolarEdge PV-Leistung auf Panelebene selbst mitloggen und per Grafana visualisieren
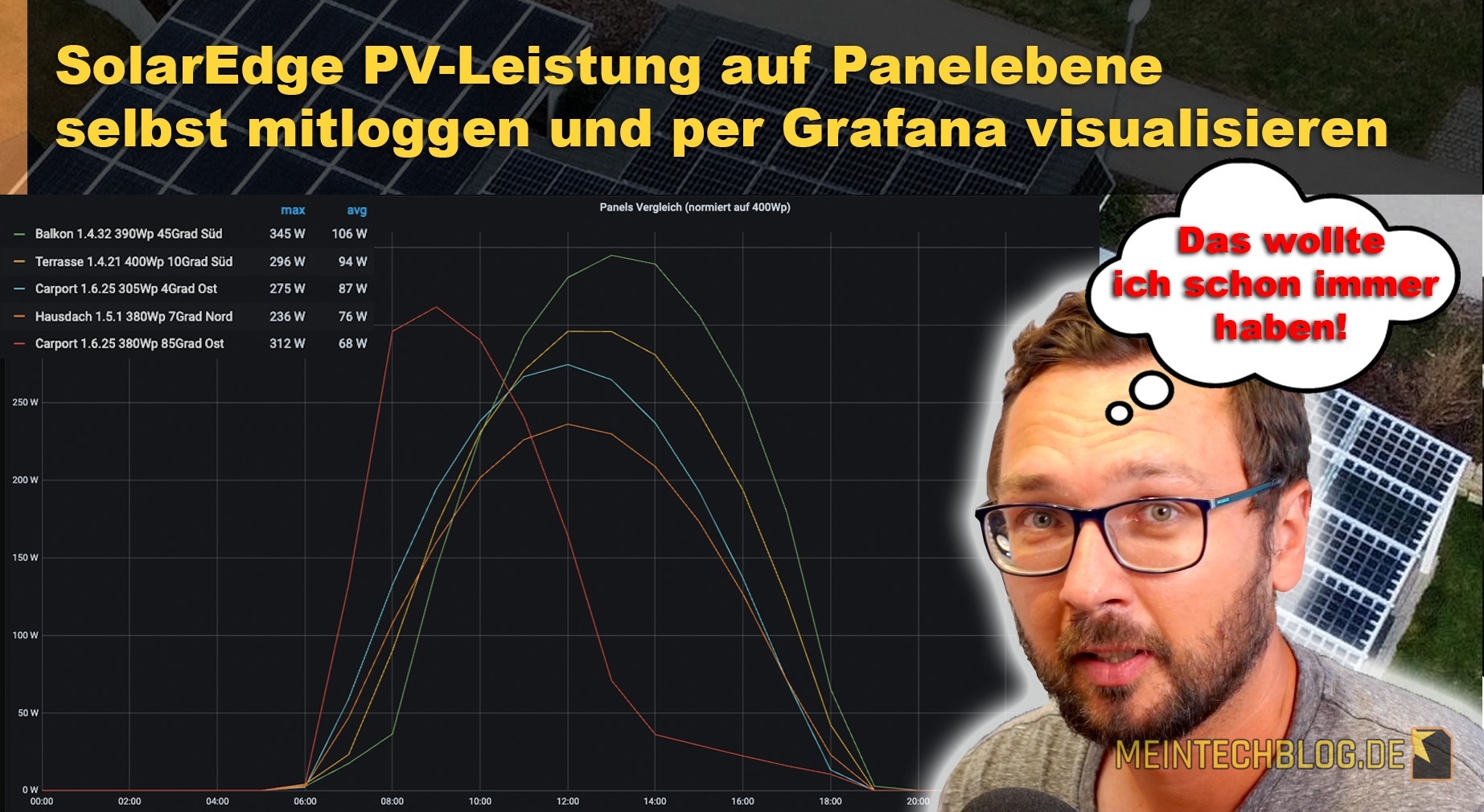
Im SolarEdge-Monitoring kann man die Panels der einzelnen Leistungsoptimierer analysieren und per csv-Datei exportieren. Cooler ist es aber natürlich, wenn man diese Daten automatisiert “abholt”, in die eigene Datenbank mitloggt und per Grafana visualisiert. Auf diese Weise lassen sich ganz neue Zusammenhänge erkennen und perspektivisch auch mit anderen Smart-Home-Parametern, die ebenfalls mitgeloggt werden, in Relation setzen.
Wie man die SolarEdge-Daten per Script zeitgesteuert abholt und am Ende eine Auswertung per Grafana aufbauen kann, ist Inhalt des nachfolgenden YouTube-Videos. Viel Spaß damit!

Mit dem Laden des Videos akzeptieren Sie die Datenschutzerklärung von YouTube.
Mehr erfahren
Links aus dem Video
00:01:50
Ich liebe SolarEdge – Analyse meines kürzlichen PV-Ausfalls
00:02:25
github – cooldil – solaredge.py
00:06:35
solaredge.py (1030 Downloads )
00:08:03
SolarEdge Panels Flow NodeRED (908 Downloads )
00:08:23
node-red-contrib-pythonshell
00:09:45
node-red-contrib-pythonshell
pip install pytz, pandas, influxdb-client, influx-client
pip3 install influxdb
sudo apt-get install python-influxdb
00:16:15
PV-Panel_Test_Grafana (1003 Downloads )






25 Kommentare
Herzlichen Glückwunsch zu deinen Erfolgen. Ich verfolge Ihre Arbeit schon seit langem. Ich habe auch ein Inselsystem gebaut, das seit 2 Jahren gut funktioniert. 16x280Ah Batterie- Neey-Balancer-JK B2A20S20P BMS -Anern 8,2KWSolar-Wechselrichter. Ist es möglich, JK-BMS-Daten über WLAN zu überwachen? Jetzt kenne ich nur die Gesamtspannung meines Anern-Wechselrichters, nicht die Spannung pro Zelle Smart ESS ap. Leider gibt es große Zeitunterschiede. Viele von uns haben dieses Problem und nicht jeder kann einen Victron-Wechselrichter kaufen. Vielen Dank für Ihre Hilfe und viele von uns sprechen kein Englisch. BÉLA
Hi,
ein JK-BMS bietet normalerweise externe Datenschnittstellen, z.B. RS485 oder Modbus. Hier lassen sich die BMS-Informationen auslesen. Dazu benötigt man dann eben die passende Soft- und Hardware. “Einfach” per WLan aus dem BMS auslesen, funktioniert dabei nicht. Einzig fällt mir hier Batrium als BMS-Lösung ein – hier lassen sich die Infos glaube ich auch per Ethernet abgreifen.
Da ich selbst Victron-Komponenten einsetze, beschreibe ich im Blog, wie die Integration mit bestimmten BMS aussieht. Bei anderen Marken habe ich leider keine eigene Erfahrung, was hier geht oder was nicht…
Viele Grüße
Jörg
Hallo Jörg,
super Beitrag, genau der Punkt der mir schon immer im Monitoring gefehlt hat. Jetzt kann ich durch die Normierung nicht mehr nur meine Ausrichtungen vergleichen, sondern auch noch Balkonkraftwerke von der Verwandtschaft die ich auch im Monitoring habe, mit dazu nehmen.
Ich habs auf nem Debian 11 System aufgesetzt mit folgenden Befehlen:
pip install influxdb-client, influx-client
pip3 install pytz, pandas, influxdb
sudo apt-get install python-influxdb
Das Thema Node-Red habe ich weggelassen und rufe das Script per cronjob auf. Hierzu habe ich in der Crontab folgenden Eintrag gemacht:
*/15 * * * * /usr/sbin/python3 /home/pi/solaredge.py
Funktioniert super!
Viele Grüße
Markus
Super, freut mich! Und danke fürs Teilen deiner ssh-Befehle! 😘
Viele Grüße
Jörg
PS: Ich feier das Script immer noch total. So macht die Auswerung endlich mal wirklich Spaß…
Korrektur:
*/15 * * * * /usr/bin/python3 /home/pi/solaredge.py
Hi Jörg, hab schon lange nach einer Lösung gesucht um genau diese Optimiererdaten abzufragen.
Habe durch Installation der von dir genannten zusätzlichen Pakete zumindest mal das Script zum laufen gebracht. Es bricht jedoch mit dem Kommentar “influxdb.exceptions.InfluxDBClientError: 401: {“error”:”username required”}” ab. Leider wird im Script kein Username abgefragt. Vielleicht hattest du das Problem auch und kennst eine Lösung.
Gruß Denis
Hallo Denis,
Bei mir ging’s auch ohne, ich hab aber gesehen dass im Script beim Aufruf des influx client die argumente für User und PW leer sind. Versuch doch mal da was einzutragen.
Puh, also bei mir lief das auch auf Anhieb mit dem Schreiben in die InfluxDB – habe hier aber auch keine Authentifizierung aktiviert, da leglich im Lan erreichbar. Hast du es schon hinbekommen?
Viele Grüße
Jörg
Hallo Markus, hallo Jörg,
habe versucht oben im Script user und password zu definieren und unten darauf zu verweisen. Leider ohne Erfolg. Daraufhin habe ich in der Influx config die Authentifizierung deaktiviert. Nun läuft es.
Wenn etwas Zeit ist versuche ich mal, ob ich durch Anpassung des Scripts auch an andere Daten der Optimirer herankomme. Z.B die Optimiererspannungen.
Gruß Denis
Hallo Denis,
Du kannst es auch einfach unten direkt mal eintragen, vielleicht gehts dann?
Weitere Werte fände ich auch total spannend, z.b. die Tagesproduktion.
Viele Grüße
Markus
Die Produktion in kWh lässt sich über die Integral-Funktion mit diesem Select-Ausdruck in Grafana (alte InfluxDB-Version) aus den viertelstündlichen Watt-Werten ermitteln.
Ein Beispiel:
SELECT integral(“146753691”) / 3600000 FROM “optimisers” WHERE $timeFilter
Spannenderweise kommen mit dieser Formel exakt die kWh-Produktionswerte heraus, die auch im SolarEdge-Portal angezeigt werden. Macht SolarEdge also anscheinend “nativ” auch nicht anders…
Viele Grüße
Jörg
SUPER, es funktioniert mit der Energieberechnung über integral. Spannend ist der Vergleich auch mit Panels von Balkonkraftwerken. So wie die Daten aussehen, kommt da mehr runter als mit Solaredge Optimieren und Wechselrichter (höngen bei mir am E3DC Ssystem).
Hallo Jörg,
Das ist ne super Info, werde ich mal ausprobieren.
Vielleicht kannst du auch mal nen Artikel oder Video über deine Grafana Dashboards machen?
Viele Grüße
Markus
Guten Morgen,
ich nutze Bookworm und bekomme die ssh Kommandos nicht zum laufen.
Fehlermeldungen sind entweder
This environment is externally managed
╰─> To install Python packages system-wide, try apt install python3-xyz, where xyz is the package you are trying to install.
und/oder
E: Unable to locate package python3-pytz
Hat da jemand Erfahrungen oder eine gute Idee?
Vielen Dank,
Jan
Hi Jan,
kenne mich mit Bookworm nicht im Detail aus, aber wie die Fehlermeldungen schon sagen, musst du Python installieren…
Vermutlich klappt das z.B. mit dem Befehl
sudo apt update
sudo apt install python3.12
Je nach Benutzer mit ohne ohne “sudo” am Anfang…
Und Version .12 scheint aktuell das neueste Release zu sein…
Viele Grüße und Erfolg
Jörg
“pytz” ist unter Debian inzwischen im Paket “python3-tz”. Anleitungen aus der Steinzeit?
Nein, die Fehlermeldung sagt nicht, dass er Python installieren muss. Das hat er schon, sonst gäbe es “pip” nicht. Abgesehen davon gibt es kein Debian-System ohne Python, das wird für den “Basisbetrieb” benötigt.
Ok guter Punkt Matthias,
kannst du dir dann vorstellen, wo Jans Problem liegt bzw. behoben werden kann?
Viele Grüße
Jörg
Hab ich doch geschrieben: “apt install python3-tz”.
Haha danke, hatte ich nicht gecheckt… :DDD
Guten Abend,
danke für die Mühe! Ich habe die Lösung gefunden. Es liegt an Python, nicht an Raspbian Bookworm:
In previous versions of the operating system, it was possible to install libraries directly, system-wide, using the package installer for Python, commonly known as pip. You’ll find the following sort of command in many tutorials online.
In newer versions of Raspberry Pi OS, and other operating systems, this is disallowed. If you try and install a Python package system-wide you’ll receive an error similar to this.
Mehr Details hier: https://www.raspberrypi.com/documentation/computers/os.html#python-on-raspberry-pi , damit läuft es jetzt perfekt.
Danke nochmals & Gruss, Jan
Hallo,
Erstmal danke für den Blogpost. Ich habe schon lange nach einer Möglichkeit zum Auslesen der Modul-/Optimiererleistungen gesucht.
Der Umweg über Python in Node-Red hat mir aber irgendwie missfallen. Ich habe mir deswegen die Mühe gemacht und das ganze in einen eigenen Node verpackt (node-red-contrib-solaredge-optimizers)
Neben den eigentlichen Daten kann man optional auch noch die zusätzlichen Infos zu den reporter IDs automatisiert auslesen lassen (Beschreibung, Typ, Serien-Nummer, Hersteller).
Optional kann man sich die Daten auch gleich passend für den InfluxDB bulk data node formatieren lassen (getestet für InfluxDB 2.0). Hier werden die Zusatzinfos dann gleich als tags angeheftet.
Hier der Link zum Node:
https://flows.nodered.org/node/node-red-contrib-solaredge-optimizers
Hallo Daniel,
das klingt interessant und ich wollte es auf meiner NodeRed installation auf einer Synology Diskstation testen.
Leider lässt sich dort der node nicht installieren. “Unsupported engine”.
Gruß
Maze
*edit* Dummerweise läuft der “lates” Docker heute noch auf NodeJS 16.20.2
Hab jetzt auf “latest_v18” gewechselt und werde es mal testen.
Noch ein paar Hinweise, für alle, welche den direkten “Solaredge-Optimizer” Node verwenden wollen:
Als “Eingang” habe ich einfach einen leeren Trigger mit 15 Minuten Intervall definiert.
Dann den SolarEdge-Optimizer-Node einrichten wie in dem Link beschrieben.
An den Ausgang dann den “influx batch” node anschließen und dort dann mit InfluxDB 2.0 verbinden und Organization und Bucket eintragen.
!WICHTIG! Die Time Precision muss auf Milliseconds (ms) stehen!
Dann läuft auch schon alles und man bekommt auch die Metadaten der Panele mitgeliefert.
Gruß
Maze
Freut mich, dass es jetzt läuft. Leider verwende ich ein Package, dass NodeJS 18 oder höher voraussetzt. In das Problem bin ich selbst bei der Verwendung mit meinem NodeRed in Docker gelaufen.
Für die direkte Verwendung mit InfluxDB gibt es auch einen Flow in den Beispielen. Darin sollten die Einstellungen für den Batch-Node hoffentlich auch ersichtlich sein.